
生信数据格式

生信数据格式
泡泡GENBANK
GenBank是一个由美国国家生物技术信息中心(NCBI)维护的数据库,它是一个免费的数据库,包含了大量的核酸序列和蛋白质序列。这些数据包括了基因组、mRNA、EST、蛋白质等。GenBank数据库中的数据是以文本的形式存储的,每一条序列数据都有一个唯一的标识符,这个标识符是一个以“LOCUS”开头的行,后面跟着这条序列的名字。GenBank数据库中的数据是以一种叫做GenBank格式的格式存储的,这种格式是一种文本格式,它包含了序列的名字、序列的长度、序列的来源、序列的特征等信息。
- 例如文件NC_045512包含以下信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20LOCUS NC_045512 29903 bp ss-RNA linear VRL 18-JUL-2020
DEFINITION Severe acute respiratory syndrome coronavirus 2 isolate Wuhan-Hu-1,
complete genome.
ACCESSION NC_045512
VERSION NC_045512.2
DBLINK BioProject: PRJNA485481
KEYWORDS RefSeq.
SOURCE Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2)
ORGANISM Severe acute respiratory syndrome coronavirus 2
Viruses; Riboviria; Orthornavirae; Pisuviricota; Pisoniviricetes;
Nidovirales; Cornidovirineae; Coronaviridae; Orthocoronavirinae;
Betacoronavirus; Sarbecovirus.
REFERENCE 1 (bases 1 to 29903)
AUTHORS Wu,F., Zhao,S., Yu,B., Chen,Y.M., Wang,W., Song,Z.G., Hu,Y.,
Tao,Z.W., Tian,J.H., Pei,Y.Y., Yuan,M.L., Zhang,Y.L., Dai,F.H.,
Liu,Y., Wang,Q.M., Zheng,J.J., Xu,L., Holmes,E.C. and Zhang,Y.Z.
TITLE A new coronavirus associated with human respiratory disease in
China
JOURNAL Nature 579 (7798), 265-269 (2020)
...
获取GenBank文件1
bio fetch NC_045512 > NC_045512.gb
GeneBank转为fasta1
cat NC_045512.gb | bio fasta > NC_045512.fa
GeneBank转为gff31
cat NC_045512.gb | bio gff > NC_045512.gff
GeneBank中提取基因序列1
cat NC_045512.gb | bio fasta --gene S
GeneBank中提取CDS序列1
cat NC_045512.gb | bio fasta --type CDS
FASTA
FASTA格式一种记录序列的格式,是一种纯文本格式,用于存储核酸序列和蛋白质序列。FASTA格式的文件以“>”开头,后面跟着这条序列的名字,然后是这条序列的序列信息。FASTA格式的文件可以包含多条序列,每一条序列都以“>”开头。
1 | >NC_045512.2 Severe acute respiratory syndrome coronavirus 2 isolate |
根据ID获取FASTA文件1
bio fetch NC_045512 -format fasta
FASTQ
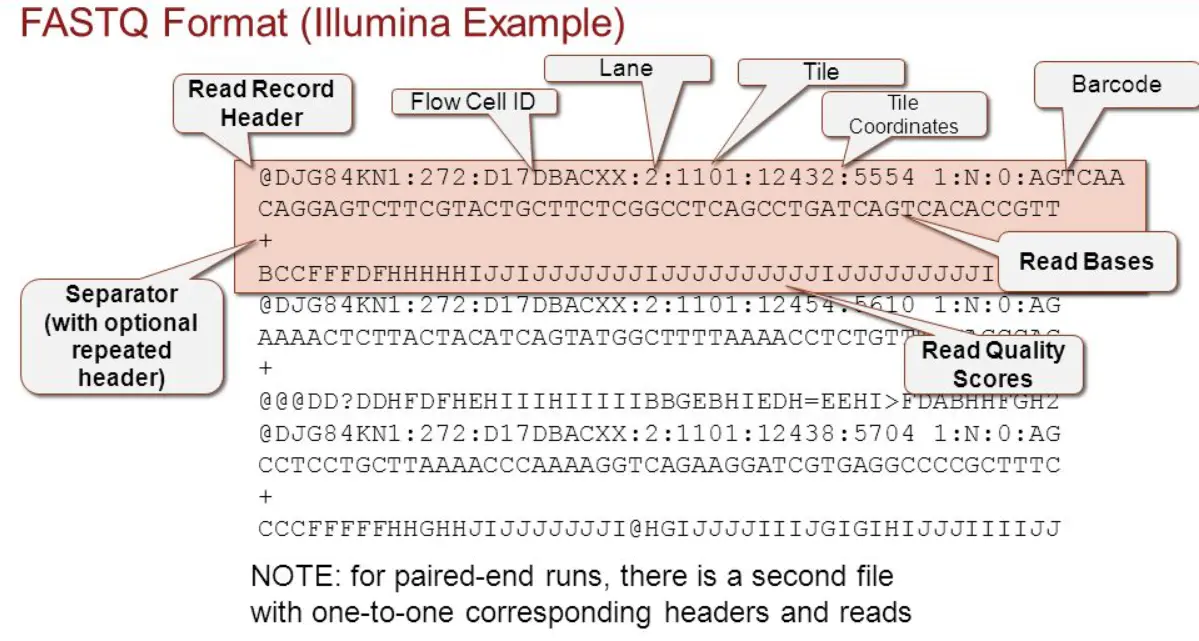
通过测序,一般拿到的数据是.fastq或者.fq的原始数据格式,该数据包含所有的reads信息,其中一条reads主要包含以下4行信息:
第一行主要储存序列测序时的坐标等信息,可用于区分来源;
第二行是测序得到的序列信息,一般用ATCGN来表示,其中N表示荧光信号干扰无法判断到底是哪个碱基;
第三行以“+”开始,可以储存一些附加信息,一般是空的;
第四行储存的是质量信息,与第2行的碱基序列是一一对应的,其中的每一个符号对应的ASCII值成为phred值,可以简单理解为对应位置碱基的质量值,越大说明测序的质量越好。不同的版本对应的不同。
GTF
gtf格式是一种用来注释金银的数据格式,一般用来注释基因组的结构信息,包括基因的位置、外显子的位置、内含子的位置等。gtf格式的文件是一种文本文件,它包含了一些列的注释信息,每一行都是一个注释信息,每一行都包含了一些列的信息,这些信息之间用制表符分隔。gtf格式的文件一般包含了一些列的信息,这些信息包括了基因的名字、基因的来源、基因的类型、基因的位置等。
SAM












