
tidyverse:处理关系数据

AI-摘要
海底捞里没有鱼 GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
tidyverse:处理关系数据
泡泡文档使用数据源说明
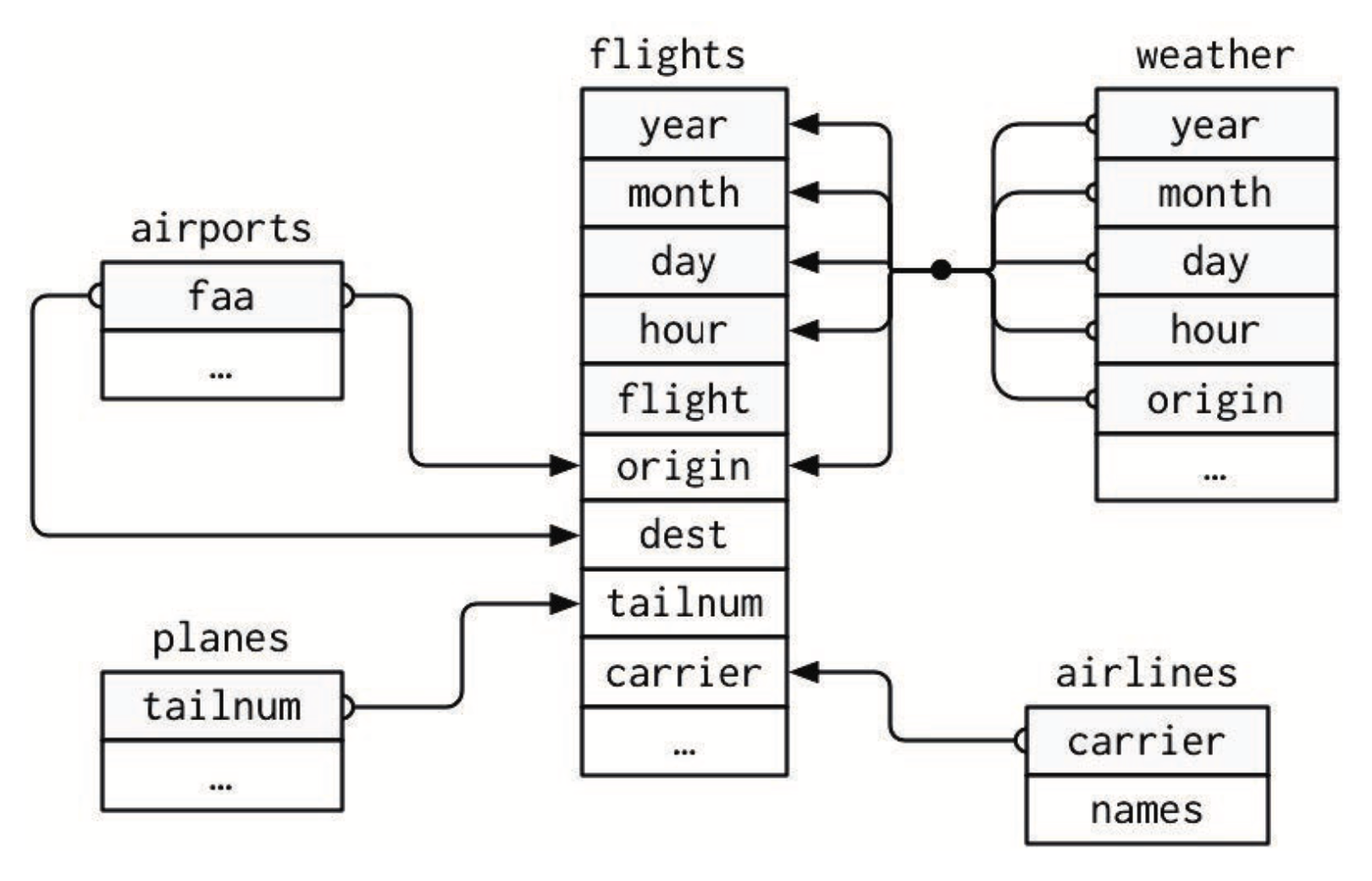
文档中举例除了使用自建数据外,我们需要使用 nycflights13。这个数据包含了 2013 年从纽约市出发的所有 336 776次航班的信息。该数据来自于美国交通统计局, 可以使用?nycflights13 查看其说明文档。包括flights, airports, planes, weather, airline五个数据框。 文档中如出现此类数据对象,不再另行说明。
- flights: 包含航班信息
- airlines:可以根据航空公司的缩写码查到公司全名。
- airports:给出了每个机场的信息,通过 faa 机场编码进行标识。
- planes:给出了每架飞机的信息,通过 tailnum 进行标识。
- weather:给出了纽约机场每小时的天气状况。
R包使用:1
2library(tidyverse)
library(nycflights13)
相关概念
- 键:用于连接每对数据表对变量称为键,键是能唯一标识观测的变量(或变量集合)
- 主键:唯一标识其所在数据框的观测
- 外键:唯一标识另一个数据表中的观测
- 代理键:一个表格没有主键时,使用mutate()和row_number()函数人为添加的一个主键称为代理键
合并连接
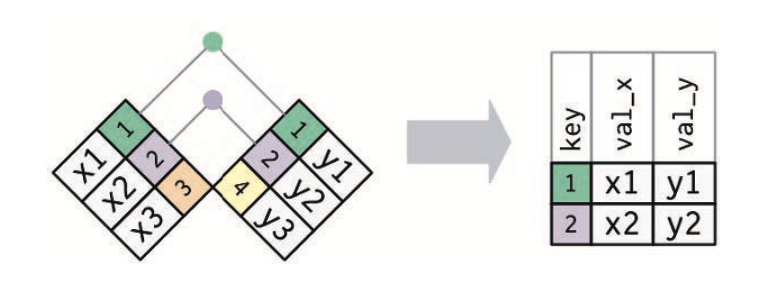
合并连接将两个表格中的变量进行组合,通过两个表格中键匹配观测,然后将一个表格中的变量复制到另一个表格中。
内连接 inner_join()
保留X和Y中共有的观测
1 | # 数据构造 |
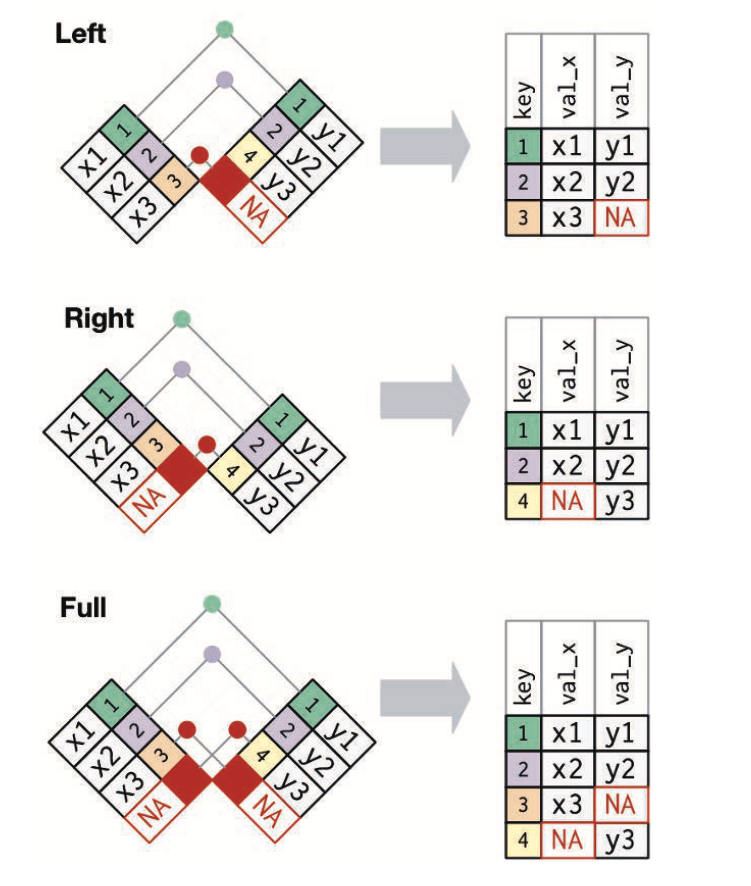
- 左连接:保留x中的所有观测
- 右连接:保留Y中的所有观测
- 全连接,保留X和Y中所有观测
1 | # 左连接 |
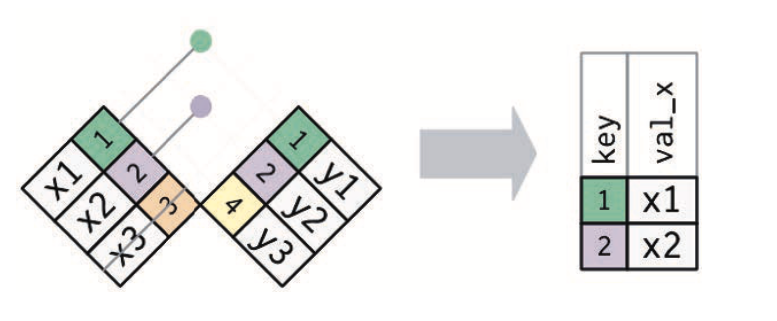
筛选连接
根据匹配的键,筛选数据表中的观测
半连接 semi_join(x, y)
保留X表中与Y表中的观测相匹配的所有观测
例:根据表flights找出飞往最受欢迎的10个目的地的航班信息
1 | # 找出最受欢迎的10个目的地 ----------------------------------------------------------- |
反连接 anti_join(x, y)
丢弃X表中与Y表中的观测相匹配的所有观测
例:找出flights 中在 planes 中没有匹配的记录
1 | flights %>% |
集合操作
集合操作要求X和Y具有相同的变量
模拟数据构建:
1 | df1 <- tribble( |
intersect(x, y)
返回既在 x 表,又在 y 表中的观测。
1 | intersect(df1, df2) |
union(x, y)
返回 x 表或 y 表中的唯一观测。
1 | # 注意,我们得到了3行,而不是4行 |
setdiff(x, y)
返回在 x 表,但不在 y 表中的观测,或反之。
1 | setdiff(df1, df2) |
注意事项
- 找出能唯一标识的主键
- 确保主键中没有缺失值
- 检查外键是否与另一张表主键匹配
相关问题
- 验证主键是否是唯一标识
1 | # 验证tailnum是否为planes表中的唯一标识 |
- 两个表中变量名不同如何进行连接
1 | # 使用 by = c("a" = "b") 形式进行连接 |

评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果










